导航
行测
言语理解
判断推理
数量关系
资料分析
公基常识
申论
公安
时政
其他
搜索
首页
Bee
列表
2025/4/19
申论
贯彻执行(公文写作)
题型分类 通知 适用于批转下级机关的公文,转发上级机关、同级机关和不相隶属机关的公文,传达要求下级机关办理和需要有关单位周知或执行的事项。通知,是向特定受文对象告知或转达有关事项或文件,让对象知道或执行的公文。一般分为发布性通知、批...
584阅读
0评论
2025/4/19
申论
综合分析
一、题型概述 定义:综合分析类试题是以分析为表现形式,综合考查应试者系统分析问题的一种试题类型,要求能够准确把握题目要求,条理清晰、简明扼要地分析问题,揭示问题的本质与引申意义,阐释独立思考所得的观点。 提问方式:“受到哪些启示”、&...
558阅读
0评论
2025/4/19
申论
提出对策
提出对策 一、对策找取 1、寻找材料直接对策: 从材料中寻找作答要点,是最基础的手段,同时也是提出对策题型作答的基础方法,也属于归纳概括的一种,本篇重点讲解原因推对策。在解题过程中,要注意文中一些重要的词汇,...
640阅读
0评论
2025/4/19
申论
材料阅读技巧
材料阅读技巧 粗读:先浏览材料,迅速把握材料整体结构,有的放矢,提升阅读速度。 精读:然后带着问题,一句一...
620阅读
0评论
2025/4/19
公基常识
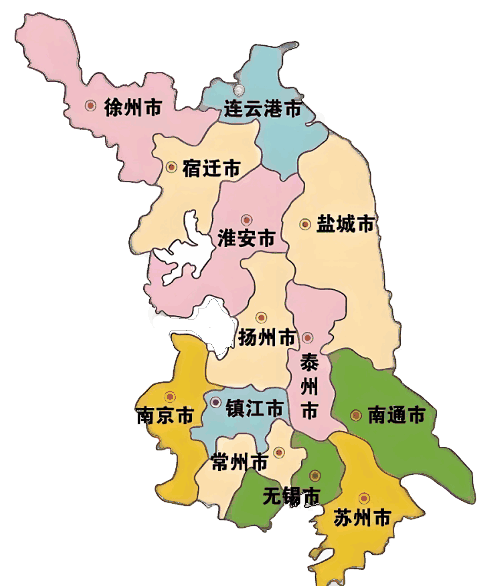
江苏省情
一、江苏概况 江苏,简称“苏”,省会南京,地处中国大陆东部沿海地区中部,长江、淮河下游,东濒黄海,北接山东,西连安徽,东南与上海、浙江接壤,是长江三角洲地区的重要组成部分,介于东经116°18&rsqu...
656阅读
0评论
2025/4/19
公基常识
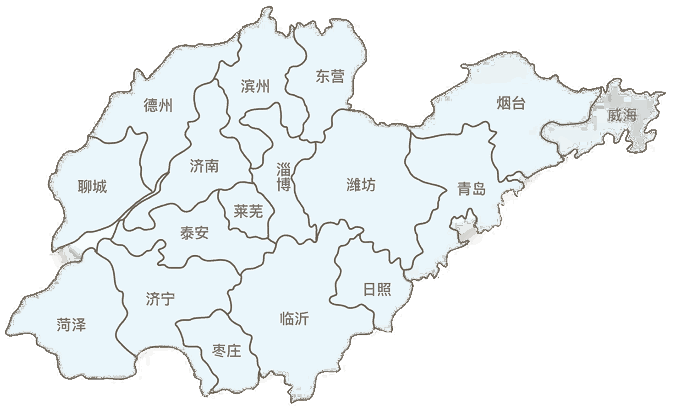
山东省情
一、历史沿革 山东是中华民族古老文明发祥地之一。已发现最早的山东人——“沂源人”,可以把山东的历史上推到四五十万年以前。沂源县发现的距今四五十万年前更新世的“沂源人”化石,为直立人在中国...
600阅读
0评论
2025/4/19
公基常识
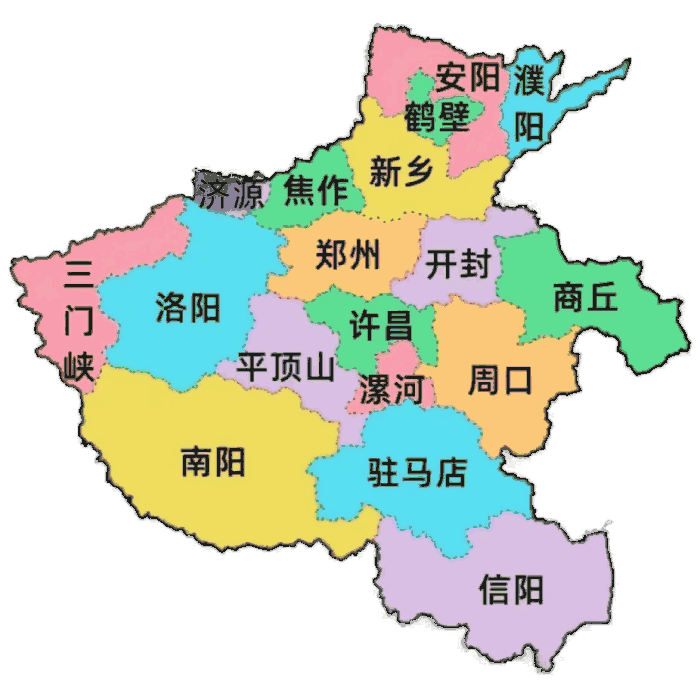
河南省情
一、地理地貌 地理位置 河南位于我国中东部、黄河中下游,因大部分地区位于黄河以南,故称河南。(现在河 南河北以漳河为界)远古时期,黄河中下游地区河流纵横、森林茂密、野象众多(河南曾经 适宜大象生活),河南又被形象地描述为人牵象之地,...
583阅读
0评论
2025/4/19
公基常识
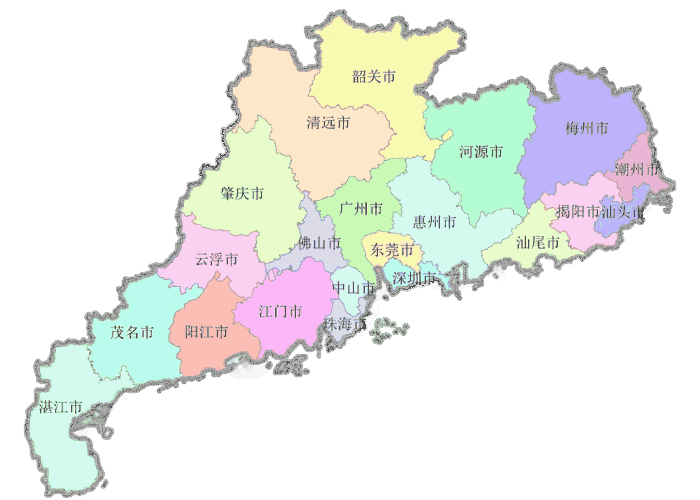
广东省情
一、广东概况 广东省,地处欧亚板块与太平洋板块交接处,简称粤,中华人民共和国省级行政区,省会是广州市。地处中国大陆最南部,东邻福建,北接江西、湖南,西接广西,南邻南海。截至 2023年12月,下辖 21个地级市、65 个市辖区,总面积...
649阅读
0评论
2025/4/19
公基常识
党的创新理论
“两个确立”:十九届六中全会通过的《中共中央关于党的百年奋斗重大成就和历史经验的决议》提出,确立习近平同志党中央的核心、全党的核心地位,确立习近平新时代中国特色社会主义思想的指导地位。 “四个意识”:政治意识、大...
586阅读
0评论
2025/4/19
公基常识
中国特色社会主义理论体系
中国特色社会主义是历史和人民的选择,建设中国特色社会主义,总依据是:我国处于并将长期处于社会主义初级阶段。 内容上:2007 年党的十七大:中国特色社会主义理论体系,就是包括邓小平理论、‘三个代表&rs...
714阅读
0评论
2025/4/19
公基常识
毛泽东思想
一、毛泽东思想的形成和发展 形成条件 时代背景:俄国十月革命开辟了世界无产阶级社会主义革命的新时代。 物质基础:中国社会新的生产力的增长。 阶级条件:中国工人运动的发展。 理论基础:马克思主义在中国的广泛传播及其与中国优秀传统文化的融合。 实践基础:中国共...
560阅读
0评论
2025/4/19
公基常识
马克思主义哲学
导论 马克思主义的科学内涵:马克思主义是由马克思和恩格斯创立并为后继者所不断发展的科学理论体系,是关于自然、社会和人类思维发展一般规律的学说,是关于社会主义必然代替资本主义、最终实现共产主义的学说,是关于无产阶级解放、全人类解放和每个人自由而全面发展的学说,...
633阅读
0评论
2025/4/19
公基常识
荣誉成就
一、国家勋章和国家荣誉 国家主席在2024年 9 月 13 签署主席令,授予 15 人国家勋章、国家荣誉称号。授予王永志、王振义、李振声 黄宗德“共和国勋章”。授予迪尔玛·罗塞芙(女,巴西)&l...
562阅读
0评论
2025/4/19
公基常识
公文篇
公务文书是法定机关与组织在公务活动中,按照特定的体式、经过一定的处理程序形成和使用的书面材料,又称公务文件。无论从事专业工作,还是从事行政事务,都需要通过公文来传达政令政策、处理公务,以保证协调各种关系,使工作正确地、高效地进行。&z...
565阅读
0评论
2025/4/19
公基常识
管理篇
一、管理学基础 管理职能 计划职能:首要职能,是对未来活动进行的一种预先的谋划。 组织职能:为实现组织目标, 对每个组织成员规定在工作中形成的合理的分工协作关系。分工与合作,这是管理的组织职能的两大主题。 领导职能:管理者利用组织所赋予的权力去指挥、影响和...
597阅读
0评论
2025/4/19
公基常识
国际经济
一、国际经济的基本知识 国际贸易 (一)国际贸易含义:国际贸易一般由进口贸易和出口贸易所组成,因此也可称之为进出口贸易。 贸易顺差(出超)=出口额>进口额 贸易逆差(入超)=出口额<进口额 (二)贸易保护主义: 1、含义:贸易保护主义是指在对外...
608阅读
0评论
2025/4/19
公基常识
宏观经济
宏观经济(Macro Economy或Macroeconomics)是指整个国民经济或国民经济总体及其经济活动和运行状态,也就是总量经济活动。它研究的是整体经济现象,如总供给与总需求、国民经济的总值(如GDP)及其增长速度、国民经济中的主要比例关...
566阅读
0评论
2025/4/19
公基常识
微观经济
微观经济(Microeconomic或Microeconomics)是指个量经济活动,即单个经济单位的经济活动。它研究的是个别企业、经营单位及其经济活动,如个别企业的生产、供销、个别交换的价格等。微观经济的运行以价格和市场信号为诱导,...
527阅读
0评论
2025/4/19
公基常识
收入分配
一、国民收入的分配 初次分配: 初次分配的依据主要是效率原则,即根据各生产要素在生产中发挥的效率带来的总收益多少进行分配,高效率获得高回报。 在社会分配中,初次分配注重效率,是按贡献分配。该贡献包括对创造利润有...
541阅读
0评论
2025/4/19
公基常识
市场经济理论
一、资源配置方式 经济生活的中心问题是如何实现资源的有效配置,以解决资源的有限性和需求的无限性之间的矛盾。在现代经济条件下,资源配置的方式主要有两种:计划配置和市场配置。 (一)计划配置:计划配置即计划调节,是指政府计划部门根据社会需...
526阅读
0评论
«
5
6
7
»